Rust and Haskell share a similar mechanism for polymorphism: traits in Rust and typeclasses in Haskell. This post explores their similarities and differences, as well as what’s next for both.
First, a few disclaimers.
Apologies if this post is drier than usual, I put it together to try and peel away some of the syntactic or other superficial differences in both systems, initially as part of designing a toy language that implements typeclasses. I also haven’t made the effort to come up with sensible examples for using each feature, I just have minimal ones to illustrate the concepts.
I know Rust better than Haskell, but I’m not very good at either, so sorry if I’ve misrepresented anything on either side. Let me know in the comments if you think anything is wrong or missing! My approach has mostly been to look at the Rust 2018 trait feature set, compare it to the Haskell 2010 typeclass feature set (which is generally smaller), then look at GHC extensions that bring Haskell up to par with Rust, and talk about those and anything else they let us do.
I use “typeclass” and “trait,” as well as “instance” and “implementation,” more or less interchangeably in this post when talking about the general concept. Obviously I try to stick to the idiomatic term when talking about one of the two languages in particular :).
Finally, I want to mention “Type classes: an exploration of the design space.”, by SP Jones, M Jones, and E Meijer (1998) as a great overview of the design space of typeclass features.
Simple traits and typeclasses
Traits and typeclasses are superficially similar to mainstream Java-like interfaces, but, obviously enough, they’re also not the same:
- The interfaces a type implements must be declared at the type’s definition site, and this list of interfaces is not extensible afterwards. On the other hand, a programmer can create a typeclass, then implement it for an already-declared type without modifying that type’s definition.
- Interfaces generally work with dynamic dispatch, and typeclasses with static dispatch: with typeclasses, it is possible to know which concrete function will be called at compile time. Rust supports a mechanism, trait objects, for using traits with dynamic dispatch, too.
- Perhaps most importantly, typeclasses are more flexible in the ways they allow the typeclass definition to refer to the implementing type. For instance, the implementing type can be the return type of a method in the typeclass, whereas in an interface, it can only occur as an argument.
Let’s look at the simple example of the (fictitious) ToString typeclass. It requires that implementors provide one method, to_string, taking the implementing type and returning a String. In Rust:
trait ToString {
fn to_string(&self) -> String;
}
// implementing the trait for i64
impl ToString for i64 {
fn to_string(&self) -> String { format!("{}", self) }
}
// using the trait
fn my_fn() -> String {
32i64.to_string()
}
In Haskell:
class ToString a where
toString :: a -> String
-- implementing the typeclass for Int
instance ToString Int where
toString i = show i
-- using the trait
myFn = toString 32
The main difference in this simple case is that in Rust, “the type implementing this trait / typeclass” is implicit in the block that defines the trait. Non-static methods will have a self, &self or &mut self argument, which will be of whatever type implements the typeclass. The special name Self can also be used to refer to the type:
trait Default {
fn default() -> Self;
}
In Haskell, the type for which the typeclass is implemented (what Rust calls Self) is explicitly given a name in the class definition. In the example above, it’s a; the name is declared just after the typeclass name.
Aside: Generic methods
In both languages, particular methods in a trait are allowed to involve new types that are not one of the trait or typeclass type parameters. For instance, in these examples, a / A are regular parameter types for generic methods.
trait MaybeReplace<T> {
fn maybe_replace<A>(&self, a: A) -> Either<T, A>;
}
class MaybeReplace t where
maybe_replace :: t -> a -> Either t a
Of course, this not really a feature of traits or typeclasses, more so a feature of these languages in general. However, since we’re looking at a number of places where types can appear, it’s easy to get confused. In any case, these are useful but essentially independent of other trait features we will be discussing.
Definition on type constructors, part 1
In addition to defining implementations on simple types, Rust natively supports defining trait implementations on specific instances of parametric types. For instance, the following defines a trait for the specific instance Vec<i64> of Vec:
impl MyTrait for Vec<i64> { ... }
Haskell will also accept
instance MyTrait [Int] where { ... }
but it requires the FlexibleInstances language feature to be enabled1By default, Haskell will only accept generic definitions like instance MyTrait [a] … , which applies to lists of any type of elements. FlexibleInstances lets us specialize definitions to a particular type of list, here [Int].. It might seem a little strange that this isn’t enabled by default, but allowing this type of declaration can lead to issues; we’ll discuss them when we get to definitions on generic types.
Default implementations
Ruse and Haskell both let you define implementations in the trait declaration directly. These default implementations can be overriden, and they can call other methods in the trait.
The only notable thing about this may be that it can be a bit of a footgun if you have a trait with, say, two methods, each one having a default implementation in terms of the other, for intance == and !=. This could be useful if you want implementors to only have to define one of the two, but if the implementor implements neither by accident, neither compiler will throw a warning, but an attempt to call either function will mutually recurse forever. See this Stackoverflow question for an example.
Multiple dispatch
Rust allows adding more types into the mix. In fact, instead of seeing traits as describing properties a type must have, we can see them as describing a relationship between some number of types (zero, just one as we’ve been doing so far, or several).
For instance, consider this Rust trait, which expresses the convertibility of a type into another (it’s basically Into)
trait Convert<T> {
fn convert(&self) -> T;
}
impl Convert<i64> for f32 {
fn convert(&self) -> i64 { self.round() as i64 }
}
fn main() { 42.0.convert(); }
There are two types at play in the trait definition: the implementing type, Self (which is f32 in the only implementation), and the result type, T (which is i64 in that implementation). In the presence of multiple Convert implementations, which convert function will be selected depends on both Self and T: this is multiple dispatch.
Syntactically, Self and T play a pretty different role, but they are semantically almost interchangeable. Indeed, we could exchange them and define the trait as:
trait ConvertAlt<T> {
fn convert(x: &T) -> Self;
}
// Note how we are now implementing the trait for i64 instead of f32
impl ConvertAlt<f32> for i64 {
fn convert(x: &f32) -> i64 { x.round() as i64 }
}
fn main() { <i64 as ConvertAlt<f32>>::convert(&42.0); }
Note that in both cases implementations of convert have the same effective type (&f32) -> f64, and the exact same body. The call syntax in Rust is different and much nicer in the first case, but expressiveness is the same.
In Haskell, typeclasses involving several types are forbidden by default, but can be enabled with the MultiParamTypeClasses language feature. Both typeclasses above would then translate to:
{-# LANGUAGE MultiParamTypeClasses #-}
class Convert a b where
convert :: a -> b
instance Convert Float Int where
convert = round
main = return $ (convert (22.0 :: Float) :: Int)
Dumb idea: ignoring Self in Rust
Here’s an experiment to demonstrate that Self in Rust is really a syntactic convenience. In the Convert example, you could completely ignore the Self type, and use another type parameter instead. Instead of Convert above, we could define:
trait Convert<T, U> {
fn convert(x: &T) -> U;
}
and provide an implementation of Convert for a dummy type, say ():
impl Convert<f32, i64> for () {
fn convert(x: &f32) -> i64 { x.round() as i64 }
}
This makes the syntax annoying, but it’s still equivalent to Convert and Convert2 above. For instance, if we want to have a function that’s applicable to all (T1, T2) such that T1 converts into T2, we can do
fn use_convertible<T, U>(t: T) -> U where (): Convert<T, U> {
<() as Convert<T, U>>::convert(&t)
}
We could implement instances of Convert<f32, i64> for types other than (), which would give us a type-indexed family of convert functions from f32 to i64. Does this have any practical uses? Probably not, but it’s fun to think about.
Generic implementations
In Rust, it’s possible to define instances for an entire class of types at once by using a type parameter where some of the trait types are expected. For instance, we can define
trait MyTrait {}
impl<T> MyTrait for T {}
(As a syntax note, anything that comes in the angle brackets after the impl keyword are type variables; any identifier that is not in this list is assumed by Rust to refer to a concrete type and will cause an error otherwise. Haskell doesn’t explicitly make this distinction.)
As before, Haskell also supports this… but we need the FlexibleInstances extension again:
{-# LANGUAGE FlexibleInstances #-}
class MyClass t where {}
instance MyClass t where {}
Of course, since this is a form of parametric polymorphism, this is not super useful: traits that are defined for any type at all can’t carry much information. This blog post by Bartosz Milewski has a nice introduction to why this is true, but intuitively, it’s because without knowing anything about T, we can’t call any methods on it or extract any information out of it. In fact, we only need FlexibleInstances because we’re trying to do this somewhat dumb universal implementation; we don’t have to use it if we have reasonable constraints.
So let’s look at two different ways to make use of this feature: type constructors and constraints.
Definition on type constructors, part 2
We’ve seen before how Rust (and Haskell with FlexibleInstances) allow us to write definitions on concrete parametrized types like:
impl MyTrait for Vec<i64> { ... }
and:
instance MyTrait [Int] where { ... }
Combined with generic implementations, this means we can write things like
impl<T> MyTrait for Vec<T> { ... }
Or
instance MyTrait [a] where { ... }
Which let us implement our trait or typeclass for any vector type in one fell swoop.
This can lead to issues! For instance, defining instances of MyType for both [a] and [Int] like above creates an ambiguity as it’s not clear which instance should apply to [Int] (both instance definitions match).
The same issue exists in Rust. Trying to define
impl<A> MyTrait for Vec<A> { ... }
impl MyTrait for Vec<i64> { ... }
will fail. We will come back to this when talking about coherence. For now, let’s look at constraints, another way to use parametric types which can also cause coherence issues.
Constraints
Another feature that is present in both languages are type constraints on the types involved in a trait implementation or typeclass instance (constraints are called trait bounds in Rust and as contexts in Haskell).
Placing constraints on implementations lets us implement a trait or typeclass for a whole category of types at once. For instance, we could create a trait that provides an is_empty method and provide a blanket implementation for all types that have a length.
trait IsEmpty {
fn is_empty(&self) -> bool;
}
impl<T: Len> IsEmpty for T {
fn is_empty(&self) -> bool { self.len() == 0 }
}
class IsEmpty t where
is_empty :: t -> Bool
instance (Len t) => IsEmpty t where
is_empty t = length t == 0
(I am being told the Len trait exists in neither language, but I hope this example is clear regardless.)
In Haskell with no extensions, contexts must be a list of class assertions. Each assertion must be of the form ClassName tyvar1 … tyvarn, where all of tyvar1 to tyvarn are type variables that also appear in the attached instance declaration; such an assertion means that there must be an instance of ClassName for tyvar1 … tyvarn. There are two main extensions to this:
FlexibleContextslets us use more complex constraints by allowing to replace some of thetyvars with concrete types. (There’s a little more discussion here on StackOverflow). It’s an analog toFlexibleInstances, which also lets us use concrete types instead of types variables, but in a different position. This is always possible in Rust; see for instance the Rust doc page onwhere.UndecidableInstances: this one lets us define cyclic dependencies, with which the type checker may no longer terminate. Specifically, it lifts the Paterson conditions, which together ensure that a context is always smaller (for a specific metric) than the instance definition, which proves that resolution terminates (once the context is empty). In Rust, instances are also always undecidable! And so the Rust type system is Turing-complete, just like Haskell’s with this extension. In practice, it’s relatively hard to make compilation fail to terminate, and both compilers have a recursion depth limit and no TCO, which means the compiler will abort after a finite number of steps.
In any case, this ability to specify instances under constraints seems like it could give rise to conflicts. For instance, if we have a case of “double inheritance” like Functor → Traversable and Foldable → Traversable, and we provide instances of a trait Trait for both T: Functor and T: Foldable, which of these two should the compiler select for a Traversable?
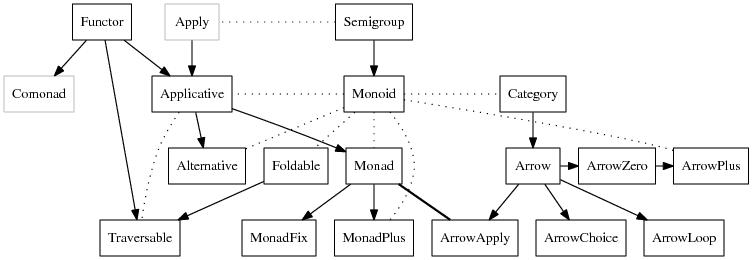
Well, both systems will just reject attempts at doing this. Haskell solves this problem by only matching on the head of an instance (the part after the =>) not the context (the part before that =>). Having two instances with the same head is an error. So a definition like
class Funct t where {}
class Fold t where {}
class Trav t where {}
instance Funct t => Trav t where {}
instance Fold t => Trav t where {}
will not compile (and there’s no way to fix it), because two instances have the same Trav t head. Rust basically does the same thing, and the following won’t compile either:
trait Funct {}
trait Fold {}
trait Trav {}
impl<T: Funct> Trav for T {}
impl<T: Fold> Trav for T {}
Finally, both languages let us define constraints on the trait itself, instead of (or in addition to) constraints on implementations. When a trait has a constraint, all implementations are assumed to have it too, and in addition, functions using the trait make use of functions provided by the supertraits. For instance, we could define a Sortable trait or typeclass that requires implementing types to also be Ord:
// The Sized requirement is a Rust-specific implementation detail
// Rust also accepts `trait Sortable: Ord + Sized` as syntactic sugar
trait Sortable where Self: Ord + Sized {
fn is_sorted(l: &Vec<Self>) -> bool;
}
class (Ord a) => Sortable a where
isSorted :: [a] -> bool
Coherence rules
For coherence in Rust, I recommend reading the readme in this git repo. Haskell’s rules are talked about in this blog post.
The problem
As we’ve alluded to in the previous section, by using generics, it’s possible create two different instances or trait implementations that apply to a particular type (or set of types, if we’re talking about multi-parameter typeclasses or traits). This is called incoherence. There’s another, maybe more obvious, way to create two different implementations of a trait for a given type: simply importing two crates or modules that define competing implementations of the same trait for the same type. This does not require any subtle language features, and shows that this is a fairly natural occurrence.
Why is incoherence an issue? A major issue with it is what Rust calls the hashtable problem (also discussed, on this Rust-internals thread and in a bunch of other places). In Rust, Hash is a trait that provides hashing functionality—only types that implement Hash can be used as keys in a hash table; a key invariant is that the same object must always hash to the same value. Now Imagine one part (let’s say crateA) of a program has one impl Hash for SomeType, and another part (perhaps defined in another crate, crateB) has a different implementation. If a hash table whose keys are SomeTypes is defined in crateA, and is passed to code in crateB, and the code in crateB uses the—different—crateB implementation of Hash for SomeType, the hash table will end up corrupted.
There are several options to deal with incoherence:
- Reject incoherence; any program that contains more than one instance of the same typeclass for one type will fail to compile. This is what Rust does (in a non-overridable manner), and also what Haskell does (but, you guessed it, you can disable that with a GHC extension).
- Accept incoherence and let the programmer deal with the possible fallout.
- Attach a particular implementation to the data structure using it, so it can keep using it in parts of the code that have a different implementation in scope. This is what Scala does, for instance, but it comes at a runtime cost.
- Prevent values produced using a particular implementation from escaping the scope where the compiler can be sure that this implementation will be used (e.g. no escape out of the crate). This needs a lot of compiler infrastructure and may be impractical. (I’m not sure if this has glaring flaws besides not being practical because I just thought of this.)
Orphan rules
Let’s start with what may be the easier part, which is the issue of getting two implementations of the same trait, for the same type, from different parts of the code.
Rust prevents this from happening through orphan rules. An impl X for Y block can only appear either in the crate where trait X is defined, or in the crate where type Y is defined. The only way to get a conflict is if the crate that defines Y, crateY, imports X from crateX, and simultaneously, crateX imports Y from crateY. This is impossible because Rust doesn’t allow cyclic crate dependencies, so there can be at most one definition of impl X for Y, and we’re safe.
Additionally, trying to define two such implementations in the same crate will also fail, but that’s easy because entire crates are compiled as one code unit, so the compiler can easily spot that issue (whereas a whole compiled crate can be imported into another crate that is not known at all at compile time—maybe it hasn’t even been written yet!).
In fact, the orphan rules are quite a bit more complex, because they allow some type variables in the type Y or in any of the trait type parameters, which is tricky. You can read up on the rules and their rationale on Niko Matsakis’ blog (I’m not aware of any more official documentation).
What does Haskell do about orphans? Basically nothing. It will emit a warning, then happily let orphan instances bite you.
Overlap rules
This is the other way of creating duplicate instances: by using generic instance creation in ways that are ambiguous for some types. A simple example in Rust might be
trait MyTrait<U> {}
impl<U> MyTrait<U> for i64 {}
impl<T> MyTrait<f32> for T {}
Or in Haskell:
class MyClass t u where {}
instance MyClass Int u where {}
instance MyClass t Float where {}
These both seem fine, but there’s a conflict for MyTrait<f32> for i64 in Rust and for MyClass Int Float in Haskell. What do the languages do?
Rust refuses to compile this code. There’s nothing you can do to convince it otherwise.
Haskell, on the other hand, will only complain if you actually try to use the MyClass Int Float instance. So quite unusually, it’s not being very strict about this whole overlapping instances situation. But you can make it even less strict! Two related options, OverlappingInstances and IncoherentInstances, let you define several instances which apply to the same types. With OverlappingInstances only, Haskell will pick the most specific applicable instance2Specifically, an instance declaration I is more specific than another I’ if you can get I from I’ by substituting type variables for concrete types. More or less. if one exists, and fail otherwise. Once again, the failure only happens if an ambiguous instance is actually used. With IncoherentInstances, Haskell will also accept the case where no most specific instance exists, and pick one at random.
Associated constants
Both in Rust and Haskell (where they are equivalent to nullary functions), traits can have associated constants. The syntax is traightforward; for instance, any type implementing this trait must provide a value of that type:
trait HasAValue {
const VALUE: Self;
}
impl HasAValue for i64 {
const VALUE: i64 = 42;
}
class HasAValue t where
value :: t
instance HasAValue Int where
value = 42
Aside: higher kinded types
Haskell provides higher-kinded type support. This feature is not directly tied to typeclasses or traits, but it interacts with it to give users more flexibility. Perhaps Haskell’s best-known typeclass is
class Monad m where
return :: a -> m a
(>>=) :: m a -> (a -> m b) -> m b
The compiler sees we apply m to some types (a and b). It infers that m is a function from type to type: given a type a, m a is also a type. We the kind of types is usually denoted as ✱, and the kind of functions from type to type (like m is), logically enough, as ✱ → ✱.
Rust, on the other hand, may in some sense understand that Option is of kind ✱ → ✱, but it won’t let us talk about Option, only about Option<T> for some T, which is of kind ✱ (think about the difference between a function f and the value f(x) for some x). We can’t define the monad trait in Rust because the Self type for Monad shouldn’t be of kind ✱! It’s an object of kind ✱ → ✱. So this abstraction of higher-kinded types is critical for expressing the concept of a functor or of a monad as a trait. This is not saying we can’t define particular monads or functors in Rust, just that we can’t abstract over their monadness.
Higher-kinded types do in fact have some level of support in Rust, as we’ll see below, but not enough for abstractions like functors and monads.
Associated types
Rust associated types
We’ve seen how we can define a trait that depends on more than one type, but we can add yet more types to the mix! Rust also supports associated types, that is, types that are provided by each implementation, and cannot be set by the caller. For instance:
trait Generate {
type Generated;
fn generate(&self) -> Self::Generated;
}
impl Generate for String {
type Generated = i64;
fn generate(&self) -> { self.len() }
}
What this means is that Generated is a type that is determined by each particular trait implementation; in other words, once the compiler has enough information to select an implementation, it will know which type to use for Generated. In particular, we know a String will always generate an i64. Contrast this with
trait Generate2<Generated> {
fn generate(&self) -> Generated;
}
For this trait, we could define two implementations, each of which will make a String generate a different type:
impl Generate2<i64> for String { ... }
impl Generate2<Vec<u8>> for String { ... }
This latter approach is more flexible in some sense, but can lead to nonsensical definitions, and the compiler will need more type annotations. For more about when it is appropriate to use associated types, see this StackOverflow answer or the RFC that introduced the type trait item.
Haskell functional dependencies
Haskell also supports something like this, but only with the FunctionalDependencies language extension (which implies MultiParamTypeClasses as above); in fact, the control is even finer.
Functional dependencies let us specify which output types (corresponding to the type members of traits in Rust) are determined by which input types.
The example above would be, in Haskell:
class Generate t o | t -> o where
generate :: t -> o
Functional dependencies are more powerful than Rust associated types. In Rust, all associated types are determined by all trait input types together (Self, plus any other types the trait depends on). In Haskell, there is no strict distinction between input types and associated types; any set of types involved in the typeclass can be declared to uniquely determine any other set. For instance, functional dependencies can be bidirectional (e.g. class X a b | a -> b, b -> a, meaning that knowing either a or b is enough to determine the other). Or a typeclass can be declared as
class X a b c d e | a b -> c, d -> e, e -> b where
...
In this case, knowing a and b together is enough to uniquely determine c, knowing d determines e, etc.
Haskell type families
Functional dependencies were the first extension to support declaring type relationships in Haskell, and while they’re extremely flexible, I’m told they suffer from slow resolution speed (the compiler basically ends up with a system of dependencies it needs to resolve), and they’re often not the simplest tool for the task.
Type families are another language extension trying to resolve the same problem, with an approach much closer to Rust’s associated types. Type families can be used within typeclasses as well as in a standalone manner, but we’ll only be looking at the typeclass case.
The basic syntax to create an associated type with a type family is
{-# LANGUAGE TypeFamilies, FlexibleInstances #-}
class Generate t where
data Generated t :: *
generate :: t -> Generated t
instance Generate String where
data Generated String = Int
generate s = length s
This is pretty close to the Rust code above: we require that each instance of Generate provide us with a type, which will also be generate’s return type. There is a little more flexibility in that we can make the types depend on some or all of the typeclass parameters, whereas in Rust they always (implicitly) depend on all input types. This is similar to how methods in Haskell may only depend on some of the types in a typeclass. (Also as a Haskell-specific note, it’s possible to declare both data and type families).
Finally, associated data definitions also work with higher-kinded types, letting us require that each typeclass instance define a type constructor. For instance, we can define
class GMapKey k where
data GMap k :: * -> *
empty :: GMap k v
This means that, assuming there is an instance for e.g. GMapKey Int, there is a type GMap Int a for any type a, and this type has one element, empty. You can see a complete example on the Haskell wiki, but here’s an example instance just to clarify things:
instance GMapKey Int where
data GMap Int v = GMapInt [(Int, v)]
empty = GMapInt []
This typeclass is impossible to define in Rust: we can try something like
trait GMapKey<K> {
type GMap<V>;
fn empty<V>() -> Self::GMap<V>;
}
But the compiler will complain. (I’ve also had to change the associated value into an associated function, because as far as I know, Rust associated constants can’t have a generic type like this, but this mostly doesn’t change the semantics—pure nullary functions and constants are mostly the same thing.)
Rust generic associated types
By now it shouldn’t come as a surprise, but there’s a Rust RFC trying to solve that last problem, too! It’s only partially implemented for now, but we can enable it in the Nighly version of the compiler. (If you’re reading this post in the future, this tracking issue) should be able to tell you more about the current status of it.
The example above now works:
#![feature(generic_associated_types)]
trait GMapKey<K> {
type GMap<V>;
fn empty<V>() -> Self::GMap<V>;
}
impl GMapKey for i64 {
type GMap<V> = Vec<(Self, V)>;
fn empty<V>() -> Self::GMap<V> { Vec::new() }
}
In effect, this is introducing limited support for higher-kinded types, in the restricted setting of trait definitions. This is actually especially useful in Rust, where lifetimes are another kind of type parameters, something with no equivalent in Haskell. The generic associated types RFC actually uses lifetime parameters as its motivating example, to define an iterator whose returned values last as long as the reference used to create it:
trait StreamingIterator {
type Item<'a>;
fn next<'a>(&'a self) -> Option<Self::Item<'a>>;
}
Here, Item is a type constructor that constructs types from lifetimes; for any lifetime 'a that the self reference has, we have a type Item<'a> , which we will use for returned objects. Again, the RFC explains this in more detail.
Conclusion and Final notes
Future evolution
A few directions in which these systems are evolving.
Instance resolution as a logic system: Maybe you’ve noticed some similarity between trying to find instances in the presence of type variables, functional dependencies, etc., as a constraint resolution problem. Indeed it can be formalized that way, and Rust’s Chalk is a project to replace the somewhat byzantine trait resolution rules with a Prolog-like system. It seems to have a decent amount of traction, and will probably be merged into rustc one day.
GHC 2021 has an accepted proposal to enable many, many language extensions by default, notably related to class and instance declarations: FlexibleContexts, FlexibleInstances, and MultiParamTypeClasses, which we’ve talked about here, would all be included.
Rust specialization is an accepted RFC to allow traits with the same head with different contexts.
Conclusion
That was a lot to cover! Rust traits and Haskell typeclasses have a lot in common, but they also differ quite a bit in the specifics. Haskell’s generally more sophisticated type system lets typeclasses express some concepts that don’t work in Rust. On the other hand, Rust traits are a good deal more versatile out of the box. On the gripping hand, this versatility can mostly be matched with a set of GHC extensions that seem common in the wild.
-
By default, Haskell will only accept generic definitions like
instance MyTrait [a] …, which applies to lists of any type of elements.FlexibleInstanceslets us specialize definitions to a particular type of list, here[Int]. ↩ -
Specifically, an instance declaration I is more specific than another I’ if you can get I from I’ by substituting type variables for concrete types. More or less. ↩
Comments